



2019년 신차의 절반 이상 음성기능 탑재 예상
자율주행 기술의 발전으로 운전자들은 운전에 대한 부담이 줄어들고 간헐적이지만 전방을 주시하지 않고도 음악이나 라디오 듣기, 문자메시지나 이메일 확인, 신문 읽기 등의 일을 할 수 있는 이차과제기법(Secondary task)의 요구가 높아지고 있다.
또한, 미래에는 자동차의 소유 개념이 공유하는 형태로 바뀔 가능성이 높아지면서 불특정 다수가 사용하는 ‘카셰어링’의 보급이 늘어나고, 주행하는 동안 시간을 유용하게 활용하기 위해 인포테인먼트 기능도 강화되고 있다.
따라서, 커넥티드카와 텔레매틱스 서비스처럼 운전자에게 필요한 정보를 효과적으로 전달하고 운전자에게 맞는 최적의 서비스를 제공하는 등 차량과 운전자 사이의 인터페이스인 HMI(Human Machine Interface) 기술이 중요시되고 있다. 이를 반영하듯 주행 중 운전자의 입력 인터페이스로 버튼, 터치 방식 이외에 음성 인식과 동작(제스처) 인식이 도입되기 시작하였다.
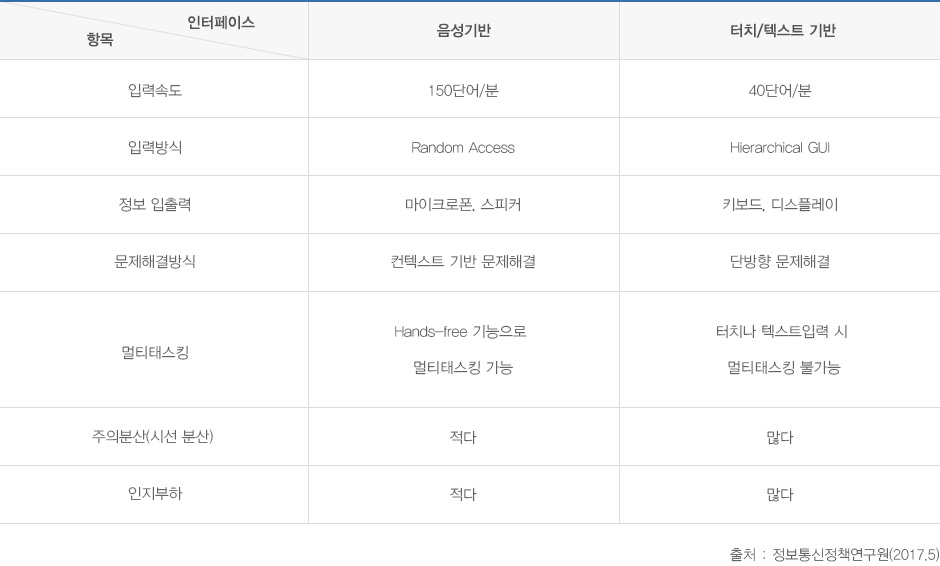
우선 음성인식은 입력 인터페이스 중 인공지능 기술을 기반으로 인공지능 자동차를 구현하는 궁극의 기술이다. 이 기술은 각종 멀티미디어 기기뿐만 아니라 사물인터넷(IoT)과 연결하는 데 가장 효과적이고 자연스러운 방법이다. 또한, 주행 중 가장 문제가 되고 있는 주의분산과 인지부하를 최소화할 수 있다. 특히 기기 조작할 때 절차를 축소하고 시각적인 정보를 대체하며, 나쁜 도로 조건에서도 다른 입력 인터페이스에 비해 쉽게 조작할 수 있다는 장점이 있다.
사용자 인터페이스 비교
음성 인식은 네트워크 유무에 따라 임베디드 방식, 임베디드와 클라우드 방식이 통합된 하이브리드 방식, 클라우드 방식으로 구분한다. 무엇보다 클라우드 기반은 음성 인식률이 높고 대화형 처리 인식이 잘 안 되는 임베디드 방식보다 더 나은 서비스를 제공할 수 있다는 점이 장점이다. 최근 부각되고 있는 애플의 시리(Siri)나 구글의 나우(Now), 마이크로소프트의 코타나(Cortana), 아마존의 알렉사(Alexa) 등은 음성 인식을 기반으로 한 개인비서 서비스다. 입력된 음성 데이터를 클라우드 서버에서 분석하고 실시간으로 검색결과를 기기로 재전송하는 대표적인 클라우드 방식이다.
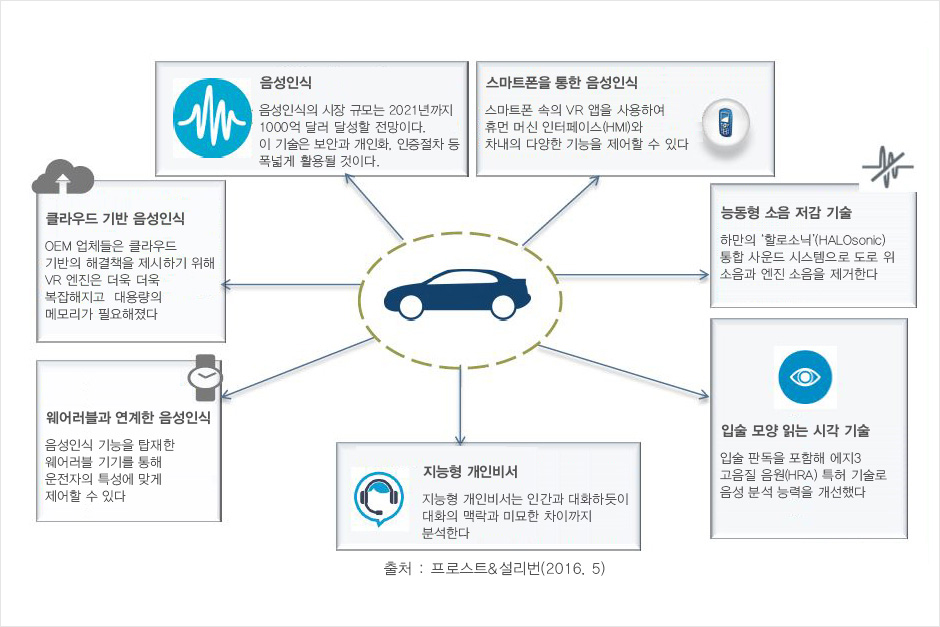
시장조사 기관 IHS 리서치에 따르면, 2019년 신차의 절반 이상이 음성인식 기능을 탑재할 것으로 내다보고 있다. 즉, 내비게이션과 음악, 전화통화 등으로 상호작용해 운전자의 안전한 주행을 돕는 것이다. 프로스트앤설리번(Frost&Sullivan)은 자동차용 음성인식 시장이 사용용도(Use case)에 따라 크게 음성 인증과 스마트폰을 통한 음성인식, 클라우드 기반 음성인식, 웨어러블 기기와 연계한 음성인식, 능동형 소음 저감 기술, 말하는 입술 모양을 읽는 시각 기술, 지능형 개인 비서 등으로 분류했다.
사용용도에 따른 자동차용 음성인식 시장
향후 음성인식 기술은 자연어 처리를 통하여 운전자의 행동이나 심리상태를 토대로 의도나 문맥을 파악하는 형태로 발전할 것이다. 또 다른 입력 인터페이스와 조합을 통하여 음성인식을 포함하는 ‘멀티 모달 인터페이스’로 진화해 나갈 것이다. 이러한 음성인식 기술이 보편화되면 운전석에 위치한 다양한 조작 버튼이 사라지는 날이 올지도 모른다.
하지만, 인공지능 자동차 실현을 위한 음성인식도 아직까지 차량 내에서 사용하기에는 완벽한 기술이라고 할 수 없다. 왜냐하면 음성 인식을 저해하는 요소들이 혼입될 경우 음성인식률이 떨어지기 때문이다. 온도와 습도 등 음파에 영향을 미치는 날씨 상태와 주행 중 노면이나 엔진으로부터 오는 노이즈, 다양한 외부 잡음(빗소리, 천둥소리, 우박, 바람, 음악 소리) 등의 영향으로 음성을 인식하지 못하거나 다른 행동을 하게 되는 부정적인 영향을 미칠 수 있다.
공교롭게 미국 자동차협회 교통안전재단(AAA Foundation for Traffic Safety)의 조사에 따르면 음성인식은 일부 부주의 운전에 영향에 미치는 것으로 나타났다.(물론 다른 인터페이스에 비해 부주의 운전에 미치는 영향이 작다) 이와 연계하여 미국 교통부(DOT)는 도로교통안전청(NHTSA)과 운전부주의 가이드라인 3단계 가이드라인을 발표했다. 현재 3단계인 음성인식 시스템에 대한 연구를 진행하고 있으며 조만간 발표될 것으로 예상된다.

BMW 7 시리즈는 핸즈오프 방식을 활용한다
제스처 인식 기술은 주행 중 전방에 시선을 유지하기 위한 목적으로 사용되는 비접촉식 인터페이스다. 기존에는 AVN(오디오·비디오·내비게이션)을 주로 조작하는 용도로 활용되었으나 최근에는 디지털 클러스트, 중앙정보표시디스플레이(CID), 헤드업 디스플레이(HUD), 시트, 사이드미러, 공조 등과 연계하여 제어하는 용도까지 넓혀가고 있다.
핸즈온 방식

핸즈오프 방식

제스처 입력방식은 컨티넨탈의 핸즈온(Hands-on) 방식과 BMW의 핸즈오프(Hands-off) 방식으로 분류한다. 향후 제스처 인식기술에도 보완이 필요하다. 우선 기기조작에 따른 기능 동작 여부를 손가락에 명확한 느낌을 전달하는 적절한 피드백이 있어야 한다. 인공지능 기술을 접목한 개인화 제스처 도입과 제스처 사용 만족도와 주행 안전을 향상시킬 수 있는 페일 세이프티(Fail-Safety) 기능이 포함되어야 한다.
또한 특정 자세나 짧은 동작으로 정확하지 않아도 차량시스템과 연계해 기능을 수행하고 다양한 문화적, 인종적 배경과 신체적 특성을 고려해 직관적이고 누구나 이해하기 쉬운 ‘유니버설 제스처’가 필요하다.
위에서 언급한 바와 같이, 두 가지 인식 기능은 사용 환경에 따라 장단점을 가지고 있다. 따라서 주행할 때 주의 분산을 야기하지 않고 사용하는 데 신뢰성이 높으며 다양한 기기와 연계 가능한 ‘멀티모달 인터페이스’ 기반의 통합적인 인터랙션 기술 개발이 필요하다.
- 박선홍
- 자동차부품연구원 박사


-
기술동향 01
음성 및 동작 인식 기술
어디까지 왔나?
-
기술동향 02
자동차 사고 회피 기술의 진화